Abstract
Inserting a 3D object into an existing scene requires more than placement — it demands that the object fits the available space while obeying geometric and physical constraints. We present ElasticFit, a framework for fit-aware 3D object insertion that combines VLM-based semantic-spatial reasoning with scene-conditioned object generation and geometry- and physics-aware fitting.
Given a natural-language instruction and an existing 3D scene, ElasticFit infers structured fitting cues that encode the target region, object orientation, support constraints, and adaptation behavior. A scene-conditioned object prior is generated and then refined through rigid, uniform, or elastic adaptation to achieve stable, physically plausible insertion. Evaluated on ReplicaCAD and Replica datasets, ElasticFit improves spatial relation success from 50.8% to 69.7% and support success from 48.3% to 91.7% over strong VLM-guided baselines.
Key Contributions
- A unified structured fitting cue representation G that jointly encodes placement geometry, adaptation strategy, and semantic conditioning — bridging high-level VLM reasoning with downstream geometric realization.
- A three-stage pipeline: semantic-spatial grounding via Set-of-Mark VLM queries, scene-conditioned 2D-to-3D object prior generation using SDXL + TRELLIS, and geometry- and physics-aware fitting with three adaptation modes (rigid, uniform, elastic).
- A physics-guided settling stage using PyBullet that refines object pose under gravity and contact dynamics for physically realistic final insertions.
- Evaluation across two benchmark datasets (ReplicaCAD and Replica) on 120 tasks spanning common placement and fit-critical conditions, outperforming LayoutGPT, Holodeck, and LayoutVLM across all key metrics.
System Design
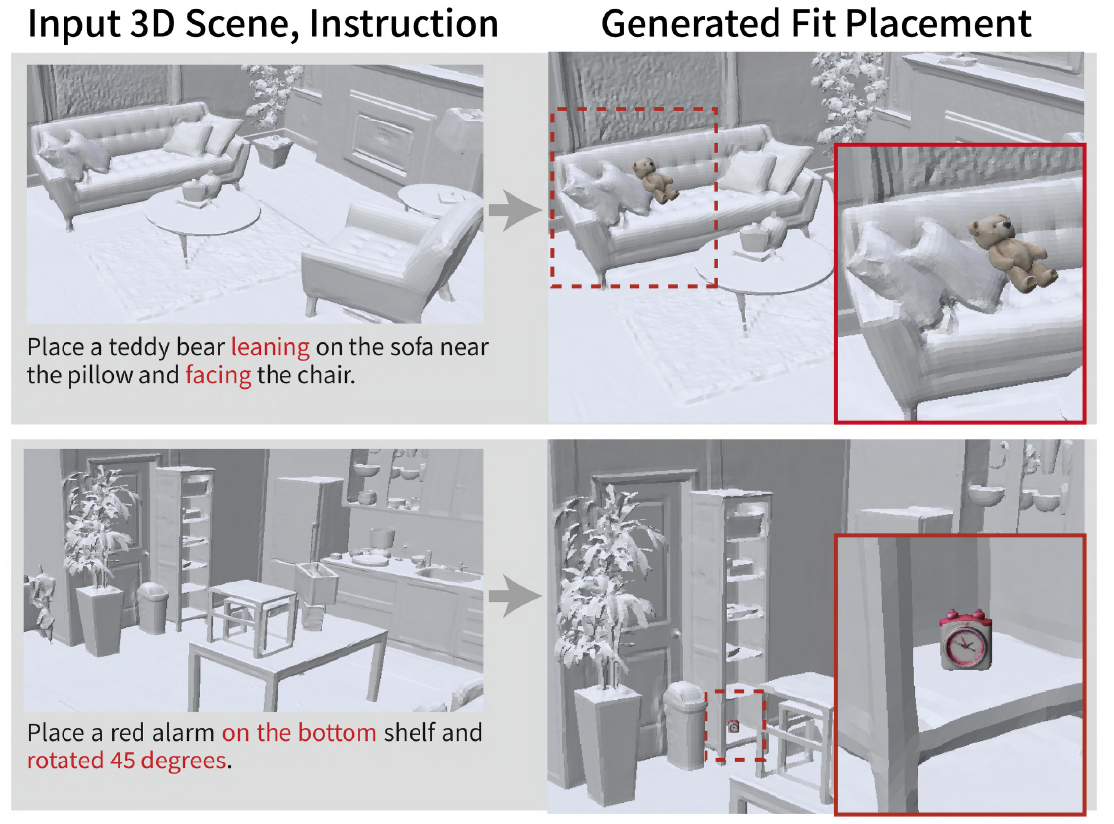
ElasticFit operates in three stages. Stage 1: Semantic-Spatial Grounding renders the scene from the user's viewpoint and constructs an XYZ buffer and semantic ID buffer. A Set-of-Mark image is generated and a VLM is queried to predict a structured JSON specifying the anchor object, target placement pixel, optional orientation cues, snapping behavior, and adaptation mode. These image-space predictions are lifted into a 3D ghost box that encodes the maximum fitting volume.
Stage 2: Scene-Conditioned Object Prior uses the ghost box dimensions to define a canvas for an SDXL-style text-to-image generator, producing a 2D object image with proportions biased toward the target fitting region. The image is then lifted into an initial 3D mesh using TRELLIS, providing a close-fit initialization for downstream refinement.
Stage 3: Geometry- and Physics-Aware Fitting refines the prior using one of three adaptation modes. Rigid mode preserves object geometry and solves for a collision-aware pose. Uniform mode optimizes a single global scale factor to fit the target region while preserving aspect ratio. Elastic mode applies anisotropic scaling along the box-local axes, enabling non-uniform adaptation to constrained or gap-like spaces. After mode-specific fitting, PyBullet physics simulation settles the object naturally on the supporting scene geometry.
Results
On the Common Placement Set (60 tasks), ElasticFit achieves 69.7% SRS, 91.7% CFR, and 91.7% SupR — improving over the best baseline (LayoutGPT: 50.8% SRS, 48.3% SupR). On the Fit-Critical Set (60 tasks including pose-and-contact and gap-fitting conditions), ElasticFit achieves 60.8% SRS, 71.7% CFR, and 83.3% SupR with a contextual plausibility score of 4.57/5. Cross-dataset validation on ReplicaCAD and Replica confirms robust performance across both clean CAD-like and noisy reconstructed scenes.